In the early- to mid-1990s, Apple produced their Macintosh Performa line of computers. These computers were meant for home users and typically came bundled with software such as ClarisWorks and Mario Teaches Typing, along with interactive tutorials teaching the basics of how to use the Mac OS. They were sold in places such as Wal-Mart and Sears.
One interesting thing about these computers is that at least initially, they did not come with any software restore disks. If something bad happened and you wiped out your system software (which was easy enough to do — somehow I did it as a kid), you didn’t have a supplied set of disks (or a CD) for restoring the software. Instead, these computers came with software called Apple Backup, and you were supposed to back up your system onto 1.44 MB floppies when you first got it. When you ran Apple Backup, it would let you choose to back up either the full hard drive or just your system folder:
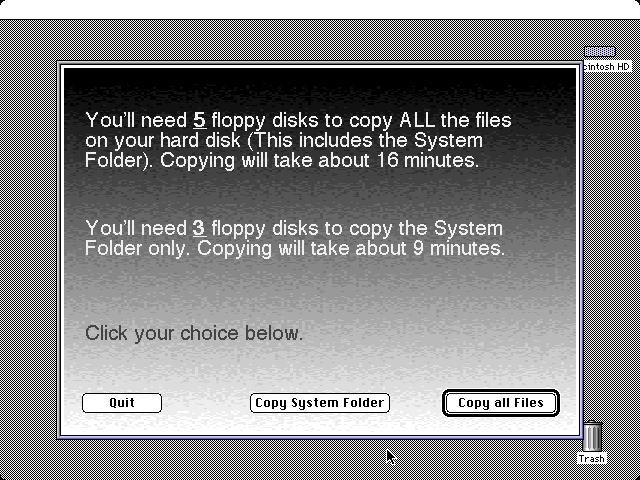
The number of disks needed here is small because I ran it on a simple barebones system to make this screenshot. With all of the bundled software on a stock Performa machine, it would have taken somewhere in the ballpark of 50 floppy disks to complete the backup of the full hard drive. Seriously, how many people would have bothered to buy all of the floppies that would have been necessary, and then actually taken the time to do it? Some people definitely did, and I’m impressed by the dedication. I know my family didn’t bother when I was growing up. It would have been more realistic to only back up user-created files, and then provide a system restore disk (or set of disks) to restore any original software, but the backup software didn’t work that way. Apple obviously learned from their mistake because they began bundling Performa computers with restore CDs at some point later on. (Note: To be completely fair to Apple, it was possible to obtain restore disks from them if you needed to restore your system and your Performa didn’t come with any.)
I ran the backup process on an old Mac for fun, and it guided me through the process of backing up the system. Click the thumbnails to see the full size, if you care:





The resulting disks were normal Mac floppy disks, named “Backup Disk 1”, “Backup Disk 2”, and so on, each containing a single 1,414 KB file named Apple Backup Data.
To restore your data after a failure, you would boot up your Performa using the Utilities disk that came with the computer. The Utilities disk contained a barebones system folder along with disk formatting/repair utilities and a program called Apple Restore. You guessed it: Apple Restore was used to restore the system. You would run it and then insert your backup floppies one at a time to restore everything you backed up.
I looked at some of Apple’s later Performa restore CDs, and interestingly enough, they came with programs called “Restore All Software” and “Restore System Software”, each with a folder full of 1,414 KB files named “Data File 1”, “Data File 2”, and so on. So presumably Apple simply used Apple Backup to back up a stock system and stuck the resulting data files onto a CD to create the restore CD.
I decided that it might be useful to have Apple Backup’s file format documented in case someone out there ends up needing to restore files from their old backups (or wants to extract files from a factory restore CD). Although backup floppies from the 90s are probably going bad by now, I think it’s still cool to have the information out there. Anyway, I decided to reverse engineer Apple Backup and one of the factory CD restore programs (which does essentially the same thing as Apple Restore). I believe I have successfully reverse engineered the Apple Backup file format.
The rest of this blog posting contains the technical details about the format of the files that Apple Backup creates.
Overall layout of an Apple Backup data file
- Type code: ‘OBDa’ (CD restore files have type ‘OBDc’ instead, but are otherwise identical in format)
- Creator code: ‘OBBa’
- There is no resource fork, and the data fork content is summarized in the table below:
| Backup disk header |
| Boot blocks |
| File #1 header |
| File #1 full path |
| File #1 data fork data (if any) |
| File #1 resource fork data (if any) |
| Zero padding to next multiple of 0x200 bytes |
| File #2 header |
| File #2 full path |
| File #2 data fork data (if any) |
| File #2 resource fork data (if any) |
| Zero padding to next multiple of 0x200 bytes |
| File #3, 4, 5, … until data file is full |
Next, allow me to describe the content of the data fork in more detail:
Backup disk header format
All offsets and lengths are in bytes. All multi-byte quantities are in big-endian format as would be expected from a Mac file format.
| Offset | Length | Name | Notes |
|---|---|---|---|
| 0x00 | 2 | Version | This spec is valid up to and including version 0x0104 |
| 0x02 | 4 | Magic number | ‘CMWL’ – identifies this file as an Apple Backup file |
| 0x06 | 2 | This disk number | Value is between 1 and the number of disks. |
| 0x08 | 2 | Total number of disks | The total number of disks used for the backup. |
| 0x0A | 4 | Backup start time | In a Mac time format (seconds since January 1, 1904 00:00:00 local time) |
| 0x0E | 4 | Backup start time | Appears to always be a duplicate of the value above |
| 0x12 | 32 | Hard drive name | The name of the hard drive that was backed up. Stored as a Pascal-style Str31 (1 byte length, 31 bytes of string data) |
| 0x32 | 4 | Total size of this file | The total size of this restore file; value typically (always?) seen is 0x161800 |
| 0x36 | 4 | Total size used in this file | The number of bytes actually used in this restore file; value is typically 0x161800 except on last disk where it is probably going to be smaller. |
| 0x3A | 0x1C6 | Unused | Filled with zeros |
Total length: 0x200 bytes
Boot blocks
These appear to be standard Mac OS boot blocks, 0x400 bytes in size. Easily seen in a hex editor because it begins with LK, and soon thereafter has names: System, Finder, MacsBug, Disassembler, StartUpScreen, Finder, Clipboard. They are written to the hard drive by the restore program when the System Folder is blessed as it’s restored. For just extracting files, they are not really relevant. They begin at an offset of 0x200 from the start of the backup file, and end at an offset of 0x600 (where the first file header begins)
File/folder header format
Each file or folder starts out with a header. Again, all offsets and lengths are in bytes, and everything is big-endian. This header will always begin on a 0x200-byte boundary; padding bytes of zero are added to the end of the previous file’s data fork/resource fork data if needed. The first file header in a backup data file is always at 0x600, immediately after the boot blocks.
| Offset | Length | Name | Notes |
|---|---|---|---|
| 0x00 | 2 | Version | This spec is valid up to and including version 0x0104 |
| 0x02 | 4 | Magic number | ‘RLDW’ – identifies this as a file/folder header |
| 0x06 | 2 | Disk number that contains first part of this file/folder | This will match the current disk number, unless this file is split across multiple disks and this is the second, third, etc. part of the file. |
| 0x08 | 4 | Backup start time | Will be the same as the time in the backup disk header |
| 0x0C | 4 | Offset of header | The offset where this header begins in the disk (example: 0x00000600 in the first file header in every disk) |
| 0x10 | 32 | File/folder name | The name of this file or folder. Stored as a Pascal-style Str31 |
| 0x30 | 2 | Which file part this is | 1, unless this is part of a file that has been split across multiple disks, in which case it will be 2, 3, etc. |
| 0x32 | 1 | Folder flags | Bit 7 = 1 if this is a folder, 0 if this is a file. Bit 0 = 1 if this is the system folder and it needs to be blessed [selected as the current system folder] |
| 0x33 | 1 | Validity flag | Bit 0 = 1 if the following file info/attributes/dates are valid. Bit 0 = 0 if this was a folder that is known to exist but its properties could not be read during the backup. If a file’s properties cannot be read, the file is skipped during the backup process. So bit 0 = 0 could only happen with folders. |
| 0x34 | 16 | FInfo/DInfo about this file/folder | A standard Mac FInfo or DInfo struct containing info about this file or folder (from HFileInfo or DirInfo) |
| 0x44 | 16 | FXInfo/DXInfo about this file/folder | A standard Mac FXInfo or DXInfo struct containing info about this file or folder (from HFileInfo or DirInfo) |
| 0x54 | 1 | File/folder attributes | Standard ioFlAttrib byte from Mac Toolbox HFileInfo/DirInfo struct |
| 0x55 | 1 | Unused | |
| 0x56 | 4 | Creation date | Standard Mac time |
| 0x5A | 4 | Modification date | Standard Mac time |
| 0x5E | 4 | Length of file’s data fork | Total length of data fork of the full restored file including all split parts (zero for folders) |
| 0x62 | 4 | Length of file’s resource fork | Total length of resource fork of the full restored file including all split parts (zero for folders) |
| 0x66 | 4 | Length of data fork provided by this disk | The length of data fork data this disk is providing for this file |
| 0x6A | 4 | Length of resource fork provided by this disk | The length of resource fork data this disk is providing for this file |
| 0x6E | 2 | Length of full file path | Maximum length of 33*50 (enough space for 50 colon-delimited path elements, with many extra bytes left over). This is the length of the string that immediately follows this header. |
Total length: 0x70 bytes. See Inside Macintosh: Files and the Mac Toolbox C headers named “Files.h” and “Finder.h” for more info on FInfo, DInfo, FXInfo, DXInfo, and ioFlAttrib. These items are where the type and creator code, invisible flag, and icon position in folder are stored, for example.
Full path format
The full path is just that: the full path to the folder or file, with the hard drive already being assumed. The components of the path are colon-delimited. The file being restored is the last component of the path. Example:
System Folder:Control Panels:Memory
(if the file being restored is the Memory control panel). It’s just printed as raw bytes, no null terminator or anything — it’s basically a Pascal string with a two-byte length, and the length is at the end of the file/folder header.
The actual file data
Immediately after the full path, the data fork bytes begin (number of bytes = “Length of data fork provided by this disk”), followed by resource fork bytes (number of bytes = “Length of resource fork provided by this disk”). It’s perfectly OK for the length of either (or both) of these to be zero. After that, there is padding (filled with “0” bytes) to the nearest 0x200 byte boundary, and then the next file/folder header begins.
When a file overflows the disk
If there is not enough space remaining on a disk for a complete file (this almost always happens at the end of each data file), the amount of file data that will fit on the disk is stored so that the full disk file size matches the size given in the disk header. Then the first file header on the next disk will be the same file’s header with the exception of the “Which file part this is” field, which will be incremented by one. It is possible for a file’s data to span several disks in this manner; the intermediate disks will only have one file header, followed by a repeat of the file path and data using up all available space on the disk.
For example: Let’s pretend you have 0x1000 bytes remaining on the current data file before its size reaches 1,414 KB. You’re ready to back up a file “Applications:TestApp” that that has a 512 KB data fork and a 128 KB resource fork. The file header will take up 0x70 of those bytes and the full path will take up 20 (0x14) of those bytes, for a total of 0x84 bytes — so there are 0xF7C (3,964) bytes left. So the file header is going to specify a data fork length in this disk of 3,964 bytes, and a resource fork length of 0 on this disk (the total lengths will be filled in as 512 KB and 128 KB though). Then the first 3,964 bytes of the data fork will be written to the file, giving it a total length of 1,414 KB. Then this disk will end. The first file header on the next disk will finish the remaining 520,324 data fork bytes and all of the 131,072 resource fork bytes, and then the next file’s header will begin on the nearest 0x200 byte boundary after that.
Conclusion
As you can see, the format is pretty simple. It’s just basically a disk header followed by a flat list of files until the end of the disk is reached. It should be possible to extract full and partial files from these backup archives even if the data files from some disks are missing. The partial files probably wouldn’t be very useful though.
The original Apple Restore utility didn’t let you pick and choose which files you wanted to restore — it just tried to restore them all, and it would ask you what to do if the file already existed and was newer than the backed up version. I see no reason why a utility couldn’t go through all of these files, give you a list of everything available, and let you selectively extract the files you want. It’s easy to detect what disk a particular backup data file came from because the disk header contains a field for what disk it belongs to.
If anyone’s interested in adding the ability to decode this format in an archive expander program, I would be happy to provide some sample data files. I may or may not decide to write a program to extract files from these backups, depending on how bored I get 🙂
Update 8/23/2022: GitHub user siddhartha77 created a new classic Mac utility called Apple Backup Extractor that can decode this file format. It can even decode what it can from an incomplete set of backup disks. If you’re looking for a way to recover data from these files, this is certainly the way to go!





Still, it was funny that they didn’t even bother to use compression for the backups.
Did you ever write that utility? I’ve got a Performa full backup here (12 disks), and would love to skip the step of doing a physical restore on a real machine.
Unfortunately I never got around to doing it. I’d definitely recommend backing up the “Apple Backup Data” file from each disk immediately though!
Hello Doug, I really appreciate your analysis about MacOS backup files. I need to recover data from 41 floppys, which only 2 of them are 12-30% unreadable. I’ve dumped the .img files of any single disk, so I’m really interested in those recovery software project you talking about. I’m not a programmer, just a medium skilled linux user, but I will help as I can, maybe working to find somebody to make a github project.
I cannot find anything useful on the net about carving data from theese files type except on your site. Thank you again for your work, I really hope that this project can move forward.
best regards,
Sergio Martinelli
Hi Sergio,
I hope that my information is able to eventually help you recover the data from those floppies. At the moment I’m just too busy to make a program to extract data from them. If you can find a programmer willing to write a utility, the info in this post, combined with sample backup files you provide, should be a sufficient specification to decode the data in the files. Note that you may run into weirdness because of how old Macs used data forks and resource forks, and didn’t use file extensions. It’s going to depend on the types of files that were backed up. As a word of advice, someone who writes a program to extract the data would probably want to extract the files with MacBinary (.bin) or BinHex (.hqx) so that the file content (both data and resource fork) can be safely extracted on an actual classic Mac or emulator.
Well, I’ve decided to formalize this a bit and get a tool going. So I’m working on getting all this data into Kaitai Struct format (http://kaitai.io) so that people can easily deploy their own parser in the language / on the platform of their choice. I’ll stick the YAML up on github when I’m done, and possibly get it pushed into the kaitai project archive.
That is great to hear! I’d appreciate it if you link to your GitHub project in the comments section of this post when you’re finished.
It’s probably also worth noting that I hacked up the “Restore All Files” application such that it doesn’t check what type of disk it’s writing to, nor whether it is booted from the restore disk. With the resulting application, I can use an emulator to boot off a disk image with a stripped down System Folder (with the system folder renamed), add in a disk image with the hacked restore app and all the restore files in it, and running the app will write all the backup data back to the boot disk, no questions asked. This won’t handle damaged backup files, but it’s great for restoring from CDs or a huge number of backup floppy (images).
First part of the ksy is complete, and I’ve tested it against a number of backup files.
I figure the first step is to create a merge script that’ll take all the backup files and build one file from them, as the format allows for larger file sizes. This way I don’t have to worry about parsing across file boundaries, but can just manually extract whatever file I want.
I’ve stuck it on Github: https://github.com/adespoton/kaitai-applebackup
With a bit of hackery, it parses the files. Interestingly, the parsing breaks on Data File 6 after the Trash folder; for some reason, the end of the folder data stops and we appear to be in the middle of junk or resource data at ee400 (it’s Finder resource data, but might not be legit). This file is supposedly in format 1.03. The next file entry begins at ef000, and the rest of the data parses correctly.
Any idea what’s happening between ee400 and ef000?
It’s probably also worth mentioning that if someone has a specific file they want to restore to a Classic OS (real Mac or emulator), they could probably use this tool to locate the file, open up the backup archive in a Classic hex editor, create a new file in ResEdit, and copy/paste the relevant sections over.
Alternatively, I could pretty easily write a tool that automatically convert each file over to MacBinary as the only thing that would really change is the file boundary. Anyone who wants to do this by hand can look at http://web.archive.org/web/20050403214802/http://www.lazerware.com:80/formats/macbinary.html
Specifically: http://web.archive.org/web/20050305044255/http://www.lazerware.com:80/formats/macbinary/macbinary_iii.html
I may try my hand at writing kaitai parsers for the three MacBinary variants as well, as the current decoders have some issues, and a tool currently being written to implement AFP 2 for OS X desparately needs MacBinary III encoding on the transport layer.
But right now, all you need is the struct I’ve already written and a hex editor (and possibly a calculator for the CRC) and you can easily convert any file in an Apple Backup file into a MacBinary III file.
Em Adespoton, that is very very cool! Great work!
I know what’s going on with Data File 6. If you look at the disk header at offset 0x06 and 0x08, you’ll see that this is disk 6 of 6. Then if you look at the disk header at offset 0x36, you’ll see that the number of bytes used in this restore file is 0xEE400. So the Trash folder is actually the final item stored in this disk (and in the entire backup). Everything after 0xEE400 is random junk.
In this case, it looks like the random junk is originally from D0800 to D1400 as part of the legitimate data stored for System Enabler 304, followed by System Enabler 308, and so on. It’s just random data that was left over in a buffer and written again as Apple Backup was finishing the file. For some reason, Apple Backup always made each file 0x161800 bytes long—even the last file that didn’t use up all of the space.
It would probably be best to trust that value at 0x36 in every backup file to determine when you’ve reached the end of that file. That’s what the restore program does. I doubt any files other than the last will be less than the max size, but who knows…
This is way too cool! It’s exciting to see some work done using the specs I reverse engineered so many moons ago. Thank you so much for doing this!
It’s all working now; I’ve removed the hacks and just need to add the documentation. So the current project can be exported to the language of your choice to parse the backup files. Next stop is MacBinary and possibly NDIF parsers so that I can easily convert a backup set to a collection of macbinary-encoded files sorted in folders, or all written on to an NDIF-encoded disk image.
Scratch doing NDIF myself; documentation’s too spotty and too much computation is needed. UDIF is MUCH easier to work with, but not universally compatible. Well, let’s see if I can whip together something that can convert from applebackup to macbinary files in a folder structure.
Right on! NDIF does sound annoying. Plus, it itself requires a resource fork, which makes it kind of a poor choice for this application in my opinion. I really like your idea of making a folder structure with MacBinary files!
I’ve compiled the structs now, so anyone can write an app in C++, C#, GraphViz, Java, JavaScript, Lua, Perl, PHP, Python or Ruby, and the heavy lifting is already done. It’d be neat if someone could write some wrapper code in JavaScript and host it so that someone could locally parse a backup set and have the file structure displayed 🙂
I think I’m going to start with a python-based extractor now; I’ve put some pseudocode on the github repo that outlines the basic logic needed to do so. Someone well versed in JavaScript could do this in that to make a web-based Apple Backup -> MacBinary converter.
I made a tiny Python script that extracts backup files into the current directory. If you run it with many backup files in order, It’ll assemble them all together and dump them in the current directory (so, consider starting in an empty directory). Here’s the script: https://gist.github.com/s4y/725955949a4cefe01fb253b1ec1d6c6c
Here’s an example usage:
for f in /Volumes/Performa\ CD/Restore\ Guided\ Tour/Data\ File\ {1..169}; do echo “$f”; python3 ~/Desktop/unbak.py “$f” || break; done
Very cool!
Forgot to mention this… a while back Siddhartha from https://os9.ca took my struct and implemented a full 68k-compatible app to extract the backups:
https://macintoshgarden.org/apps/apple-backup-extractor
Placing that here so those searching for AppleBackup related stuff will find it 🙂