Fitting in with my recent trend of repairing video capture/camera devices, this time I found a non-working NZXT Signal 4K30 HDMI capture device on eBay. The description of the item was: Tested and the unit powers on, but is not detected by NZXT Cam software. Unable to test further due to this.
When I received it, I replicated exactly what the listing said. The white light on the front turned on, but then nothing happened. No USB device was detected by my computer at all. Opening it up, I was able to get an idea of the overall architecture. Someone else has also torn this device down, so I didn’t have to start completely from scratch.
I’ve recently been on a bit of a repair kick and wanted to tell another fun repair story. I promise my blog isn’t becoming dedicated just to fixing electronics. This was an interesting story as far as parts sourcing goes though, so I thought it would be a cool one to share. Plus, you’ll get to learn how focus control works on webcams with autofocus.
I found a really good deal on eBay for two “for parts or not working” Razer Kiyo Pro webcams. These are pretty decent 1080p60 cameras with autofocus and nice image quality. Here’s the item description:
Web cam has been tested and does not power on
It looked like they were both returns to Amazon or a similar retailer, and surprise surprise, the description was completely wrong. They both powered on just fine.
One of them seemed to work great, and the other one was way out of focus and didn’t respond to any focus control commands at all. These cameras support manual and automatic focus control through software, but I just couldn’t get it to work at all on the faulty one.
There have been some past rumblings on the internet about a capacitor being installed backwards in Apple’s Macintosh LC III. The LC III was a “pizza box” Mac model produced from early 1993 to early 1994, mainly targeted at the education market. It also manifested as various consumer Performa models: the 450, 460, 466, and 467. Clearly, Apple never initiated a huge recall of the LC III, so I think there is some skepticism in the community about this whole issue. Let’s look at the situation in more detail and understand the circuit. Did Apple actually make a mistake?
I participated in the discussion thread at the first link over a decade ago, but I never had a machine to look at with my own eyes until now. I recently bought a Performa 450 complete with its original leaky capacitors, and I have several other machines in the same form factor. Let’s check everything out!
Here’s the affected section of the board before I removed the original capacitors. You can see that all three of these caps (C19, C21, and C22) have their negative side pointing upward, matching the PCB silkscreen that has the + sign at the bottom.
Here’s a weird problem that I’ve never seen before, along with my eventual hardware fix. After my previous Elgato Game Capture HD60 S HDMI capture card LED repair escapades, I recently ended up trying to find another modern revision of the same device so I could dump its SPI flash chip in order to be 100% certain that the data I put into the flash for the animations was correct for the newer model. I took a chance and bought one for cheap on eBay that was sold as not working at all, but looked like it was newer based on the case style and arrangement of the back panel:
The item description said:
Unit powers on when connected to computer, but all computers we’ve tested this with refuse to recognize it as being connected.
When it arrived, I noticed that it came with a USB A-to-C cable that wasn’t actually a SuperSpeed cable.
Earlier this year, there was some drama around the shutdown of the Nintendo Wii U’s online gaming. Team 0% had a goal of making sure that every level created in Super Mario Maker was beaten at least once. If you’re not familiar with Mario Maker, it’s a video game that lets you make your own levels in the style of several classic Mario titles and share them with the rest of the world to play. Well, it did until new uploads were disabled in 2021. By that point in time, the sequel Super Mario Maker 2 had come out on the Switch and that’s where most people were creating their levels.
The clock was ticking for Nintendo’s servers and Team 0% was so close to their goal. Eventually what it came down to was a single uncleared level: Trimming the Herbs by Ahoyo. As you can see in the video, it only takes about 15 seconds to beat. But in order to win, you have to do some crazy, precise tricks that casual players like me simply can’t do.
Some of the most talented Super Mario Maker players in the world were focused on trying to finish it before the April 8th cutoff, including sanyx91smm2, Thabeast721, and LilKirbs. It was very, very difficult. People started wondering if cheating was involved. In order to upload a level to Nintendo’s servers, you have to beat it yourself first. This serves as a way to ensure that impossible levels can’t be uploaded (although some cruel people use glitches or hidden blocks to still upload “impossible” levels).
I’m not really much of a gamer these days, but this story caught my eye at the time and inspired me to do some hardware tinkering with my own Wii U.
This post has a little bit of everything. Hardware diagnostics, some suspiciously similar datasheets from two separate Taiwan chip manufacturers, and firmware reverse engineering. Read on if that sounds like fun!
Lately, I’ve been enjoying watching random electronics repair channels on YouTube. There’s something oddly satisfying about watching someone take a broken device from totally nonfunctional to perfectly working, all by replacing a $0.05 capacitor that has failed shorted or maybe a blown $0.75 IC. Two of my favorite channels about this topic are Buy it Fix it and StezStix Fix?.
The videos inspired me. I thought, “I should totally try this!” So I went on eBay and looked for broken devices. I have a pretty decent understanding of how video encoders and decoders work, so I thought it would be a fun project to try to fix an HDMI capture card. I found a broken Elgato Game Capture HD60 S USB 3.0 device. The listing said that nothing happened when you plugged it in.
When it arrived, I was able to verify exactly what the listing said. Nothing showed up on my computer when I plugged it in. I cracked it open and had a look at what was happening internally when it powered up. I started by poking around at voltages on the board with it plugged in, and it was pretty obvious that something was dragging the power rails down. Little did I know at that point what I was getting myself into.
This is the final post in my blog series about getting my Chumby 8 from 2011 working on a modern 6.x Linux kernel, as opposed to the stock 2.6.28 kernel it came with. Here are links to all of the previous articles where I went into detail about the various obstacles I had to overcome: 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, and 12. I guess we’ll finish it off with lucky number 13.
It has been over two years since that fateful day when I started trying to get a newer U-Boot working on my Chumby to kick off this whole process! I haven’t been working nonstop on the Chumby this whole time though. I completed most of my work on this project by early 2023, and since then I’ve just been trying to catch up on writing these posts and also fixing little issues as they’ve come up. It’ll probably never be fully completed though. I will likely run into various problems in the future as new kernel versions come out and things inevitably break.
I’m not going to cover U-Boot as part of this. If you’re curious about that, check out the first post in the series. Most of the work I did was in Linux. Let’s start by looking at everything I accomplished in the kernel, grouped by subsystem. We’ll see the commits that are in the mainline kernel versus the commits that I haven’t submitted upstream for whatever reason. I’m also linking to all of the original patches on lore.kernel.org in case you want to see the related code review and discussion.
As you may remember from my last post on the subject, I fixed a couple of cheap Altera USB Blaster clones in June. I found improved open-source firmware and ported it to the previously useless CH552G-based one while fixing a bug in the process, and I soldered a slower 12 MHz oscillator into the Waveshare FT245+CPLD blaster which magically made it start working reliably in Linux.
Because I don’t know how to let things go, not to mention I find this topic interesting to write about, I bought some more cheap USB Blaster clones on AliExpress. The cheaper one ($2.45) ended up being another CH552G-based one identical to the previous one I got on Amazon, right down to the Windows BSOD problem with the stock firmware. That problem is now easy to fix by reflashing it with the open-source firmware I ported.
The slightly more expensive device ($9.34) was an FTDI+CPLD design with a completely different PCB and enclosure from the Waveshare one. The label on the front says it’s a model KRZV-REV. C. It still uses an Intel/Altera EPM3064ATC44-10 CPLD, exactly like the Waveshare. The pin mapping on the CPLD isn’t the same though.
It had pretty much the same problem the Waveshare model had, though: it worked fine in Windows, but in Linux it gave me random results. It mostly didn’t work at all. I could occasionally get it to do something successfully if I tried enough times. Also, it would fail Quartus Programmer’s JTAG Chain Debugger tests, just like the Waveshare, with “Uncertain JTAG chain” warnings.
Sometime back in 2018, I tried out a fresh install of Ubuntu MATE 18.04 on one of my computers and noticed a strange problem when I attempted to install Google Chrome. I clicked the little Firefox icon in the top panel:
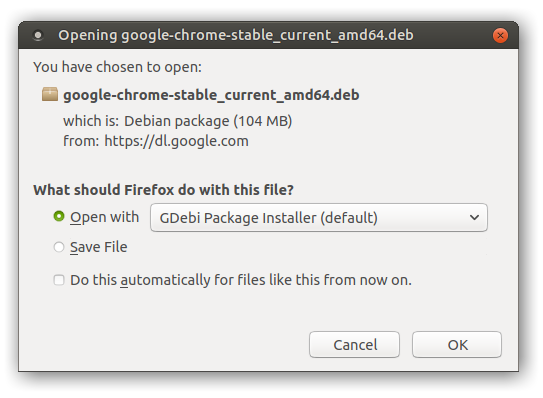
Then I downloaded the latest Chrome .deb from Google and opened it up from inside of Firefox:
At this point, GDebi popped up giving me the option to install it. Everything seemed totally normal so far.
Way back in part 2 of this series, I first got my Chumby 8 booting into a newer Linux kernel. (Here are links to parts 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, and 11 if you want to read the rest of the saga). At that point early on in the project, I had to get the UART driver working. I didn’t spend much time talking about the UART in that post, but it actually gave me a small challenge that I recently had to revisit. I thought it would be fun to tell the full story of the UART struggles I ran into.
When I was first figuring out how to configure my new kernel, I noticed that the pxa168.dtsi file included in the mainline kernel already had the UARTs added. They each had two compatible strings, in order of priority: mrvl,mmp-uart and intel,xscale-uart. This makes sense because Intel’s XScale architecture was used for many things including the PXA series. Then the PXA series was sold to Marvell in 2006, who later designed the PXA16x processor used in the Chumby 8.
Searching through the kernel sources, there were actually three drivers that reference the mrvl,mmp-uart compatible string: 8250_pxa, 8250_of, and the deprecated pxa driver. I originally tried out 8250_pxa, but I ran into a problem with it. During large transmits, for example when typing “dmesg” after the kernel booted, it would drop a ton of characters. Here’s a small excerpt of a modern recreation of the issue in a newer kernel: